base64的作用
二进制的数据,每个字符的取值范围都是[0, 255],作为ascii码解析时,只有部分可打印。
比如,我用文本编辑器vim打开一张jpeg图片,会发现内容是乱码。以下是头两行数据:
1 | ÿØÿà^@^PJFIF^@^A^A^@^@^A^@^A^@^@ÿÛ^@C^@^F^D^E^F^E^D^F^F^E^F^G^G^F^H |
我在vim下输入:%!xxd,可以查看二进制数据对应的十六进值。以下是头两行数据:
1 | 00000000: ffd8 ffe0 0010 4a46 4946 0001 0100 0001 ......JFIF...... |
注意,下面的两行和上面的两行内容长度不一定是相同的。上面的数据是遇到ascii码为换行时换行,下面的数据是每16个字节换行。
比较上下两份数据,可以看到JFIF在上面也打印了,在下面的右半部分也打印了。说明他们的数据源确实是同一份,只是展示方式不同。
显然,如果我想肉眼看这份二进制数据,或者说作为文本拷贝这份数据,16进制的格式要优于二进制ascii码格式。
但是,16进制表示法,需要两个字节才能表示表示原始数据的一个字节。比如4a464946表示JFIF。即大小增加了一倍。
有点大?于是,有人发明了base64算法。它保持了编码后可打印特性的同时,大小只增加1/3。
base64算法原理
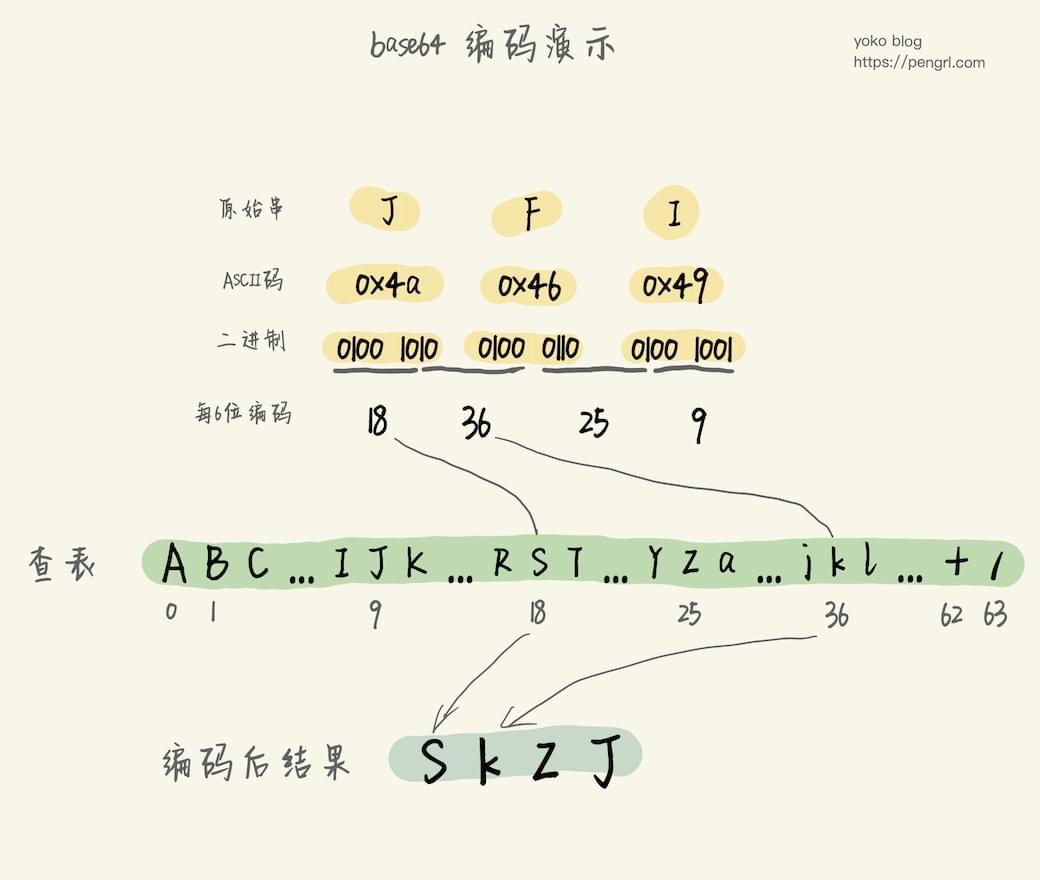
base64将原始二进制数据每三个字节(也即24位)看成一个单元,然后将24位按每6位进行一次切割,切割成4个字节。切割后每个字节的范围是[0, 63]。
由于[0, 63]的ascii码也并不都是可打印的,于是将[0, 63]再一一对应换算成一个可打印的字符。
标准文档RFC 4648对该映射关系定义如下:
1 | ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/" |
也即0对应A,1对应B,63对应/。
换算之后,三个字节就变成可打印的四个字节的内容了。
解码方的逻辑,先将每个可打印的字符按刚才的映射表反算出对应的值。然后每4个字节看成一个单位,按位运算还原出原始的3个字节。比如:解码前第1个字节的低6位作为解码后第1个字节的高6位,解码前第2个字节的低6位的前2位作为解码后第1个字节的低2位,这样就得到了解码后的第1个字节。后续依次按顺序推算。
还有一个问题,原始数据长度如果不是3的倍数怎么办?
那么无非是两种情况,一种是最后剩1个字节,另一种是剩两个字节:
- 剩余1个字节时,1个字节编码成2个字节,剩余2个字节填充为
== - 剩余2个字节时,2个字节编码成3个字节,剩余1个字节填充为
=
即base64保证了编码后的字符串长度为4的倍数。
作为url参数时有什么问题
有的人会把二进制数据用base64编码后,放入url的参数中,这么做有一个问题,base64编码后可能会出现+/=三个字符,而这三个字符会影响到整个url串的解析。
举个例子,url串https://pengrl.com/all?key=value,如果将其中的value设置成1/2=,则url串变成https://pengrl.com/all?key=1/2=。其中的/和=是不是有点傻傻分不清楚呢?
那么如何解决呢?
编码后的+和/两个符号来源于上面给出的那张映射表。于是标准文档RFC 4648中给出另一张映射表,将其中的+替换成了中划线-,/替换成了下划线_。
这里额外说一句,base64并不适合用来做文本加密,因为算法是公开的,并且它只是一种简单的查表映射,有经验的web开发者,甚至看到末尾的=都能猜到是base64编码。即使编码和解码都使用自定义的映射表,根据文本规律,也很容易破解出映射表。
剩下=,上面也说过,是由于原始数据长度不是3的倍数填充得到的,解决方法也很简单,编码时不填充,解码时剩余的不够4字节的数据按顺序解就好。
上面的两种做法,都需要保证,编码端和解码端是能对上号的。
base64主要还是对二进制做可打印编码,如果是处理url参数,最好还是使用urlencode。urlencode是啥,下回再聊。
本文完,作者yoko,尊重劳动人民成果,转载请注明原文出处: https://pengrl.com/p/20012/