本文基于Go 1.13
创建系统线程以及在系统线程间切换,会对程序的内存和性能造成较大的开销。Go的目标是尽量利用CPU多核资源。设计之初就考虑了高并发性。
M,P,G 模型
为了达到这个目标,Go拥有一个将协程调度到系统线程执行的调度器。这个调度器定义了三个核心概念,在Go源码中是这样解释的:
G - goroutinue. 协程
M - worker thread, or machine. 工作线程
P - processor, 执行Go代码时所必须的一种资源。
M必须有一个相关联的P才能执行Go代码。
以下是 P,M,G 模型的示意图:

每个协程(G)在一个分配给逻辑processor(P)的系统线程(M)上运行。来看一个小例子:
1 | func main() { |
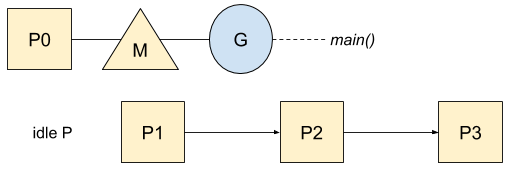
首先,Go会根据当前机器的逻辑CPU个数来创建相应数量的P,并将它们存放在一张空闲P列表中:
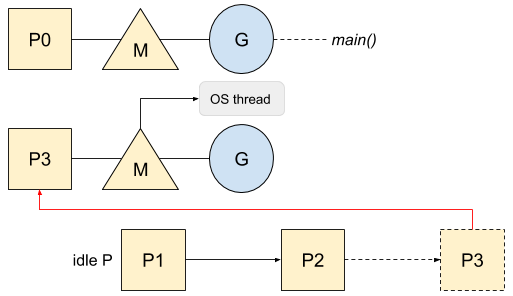
然后,新创建并等待被运行的协程会唤醒一个P来执行这个任务,这个P会创建一个和系统线程相关联的M:
和P一样,如果一个M没有工作可做了,该M会被放入空闲M链表中:
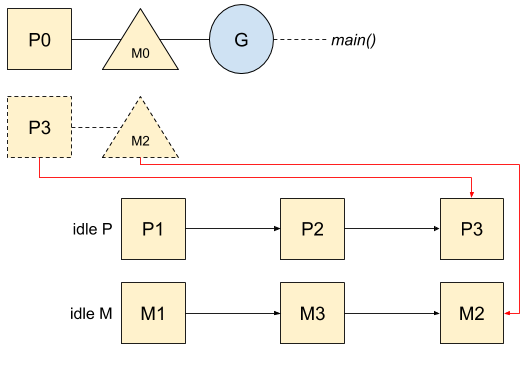
在程序启动时,Go会预先创建一些系统线程以及相关联的M。在上面的小例子中,第一个打印hello的协程会使用主协程,而第二个打印world的协程会从空闲列表中获取到一个M和一个P:
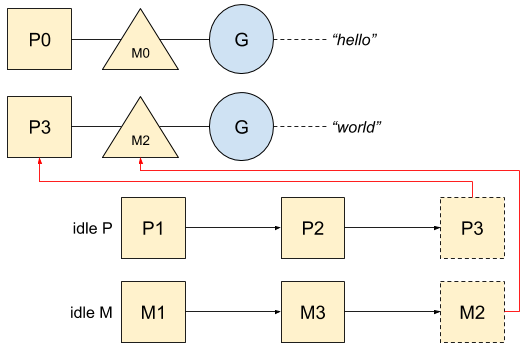
以上,我们有了一张管理协程和系统线程的全局图,让我们进一步看看Go在什么情况下会使用更多的M和P,以及调用系统调用时协程是如何被管理的。
系统调用
Go对系统调用做了优化,具体做法是在运行时对系统调用做了封装(不管系统调用是否会造成阻塞)。该部分封装代码会自动将P与线程M解除绑定,使得另一个线程M可以在这个P上运行。让我们来看一个读取文件的例子:
1 | func main() { |
以下是打开文件的流程:
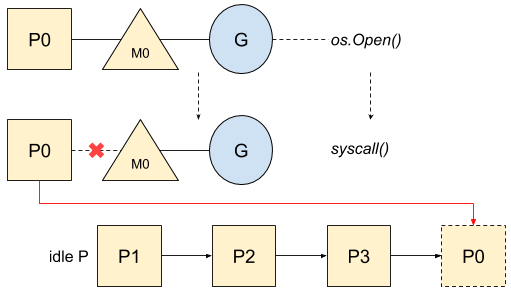
现在,P0被放入空闲列表中,可被使用。当系统调用结束之后,Go顺序执行如下流程直到其中一条规则被满足:
- 试图获取同一个
P,在我们上面的例子就是P0,如果获取到,则恢复执行 - 试图在空闲列表中获取一个
P,如果获取到,则恢复执行 - 将协程放入全局队列中,将相关的
M放入空闲列表中
并且,Go使用非阻塞I/O模式,对资源还没有就绪的情况也做了处理,比如说http请求。这种情况下首先也遵循上面所说的系统调用的流程,之后如果底层的系统调用由于资源没有就绪而返回失败时,Go会强制使用network poller,并且将该协程挂起。以下是例子:
1 | func main() { |
当底层的系统调用返回并且显式表示资源没有就绪时,协程将被挂起,直到network poller通知它资源已经就绪。这种情况下,线程M不会被阻塞:
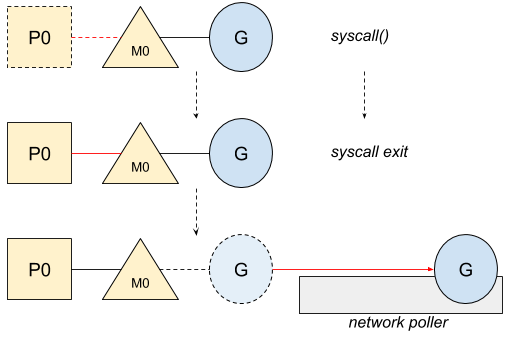
当Go调度器重新调度时,之前的那个协程将被重新运行。调度器会询问network poller是否存在之前在等待资源并且现在资源已经就绪的协程:
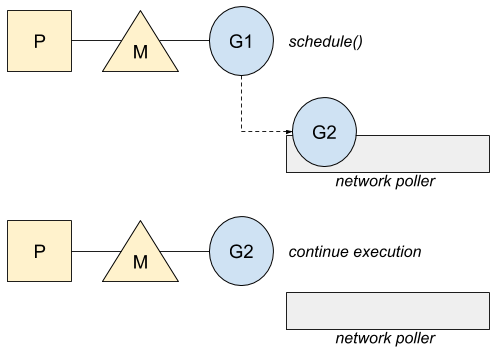
如果有多个协程就绪了,其它的协程会被放入全局等待执行队列中,稍后会被调度执行。
关于系统线程数的限制
当使用了系统调用时,Go并不限制这些可能被阻塞的系统线程的数量,以下是Go代码中的注释说明:
GOMAXPROCS变量限制的是用户层面Go代码的系统线程数量。对于可能造成阻塞的系统调用的线程数是不做限制的;它们不计算在GOMAXPROCS限制之中。
以下是一个例子:
1 | func main() { |
以下是使用tracing工具,查看程序创建的线程数量:
值得一提,由于Go可以复用系统线程,所以工具查看到的线程数要小于例子中for循环的次数。
英文原文地址:Go: Goroutine, OS Thread and CPU Management
本文完,作者yoko,尊重劳动人民成果,转载请注明原文出处: https://pengrl.com/p/29953/